Digital Japanese Literature: Aozora Bunko
Introduction

Higuchi Ichiyō, featured at Aozora
Aozora Bunko (青空文庫) is a digital archive of Japanese literature in the public domain. In addition to its web presence, the corpus is also available on GitHub where it can be downloaded in its entirety. This makes it possible to perform a distant reading of the collection, and the following information serves as a general introduction for data analysis and parsing.
First and foremost, you will need to clone the GitHub repository to your computer. A warning: the download is quite large (~4 GB) and therefore may take some time. To install the repository locally, access the command line and input the following:
git clone https://github.com/aozorabunko/aozorabunko.git
If you have not yet installed git on your computer you will first need to follow these directions for your respective operating system.
Aozora Bunko Schema
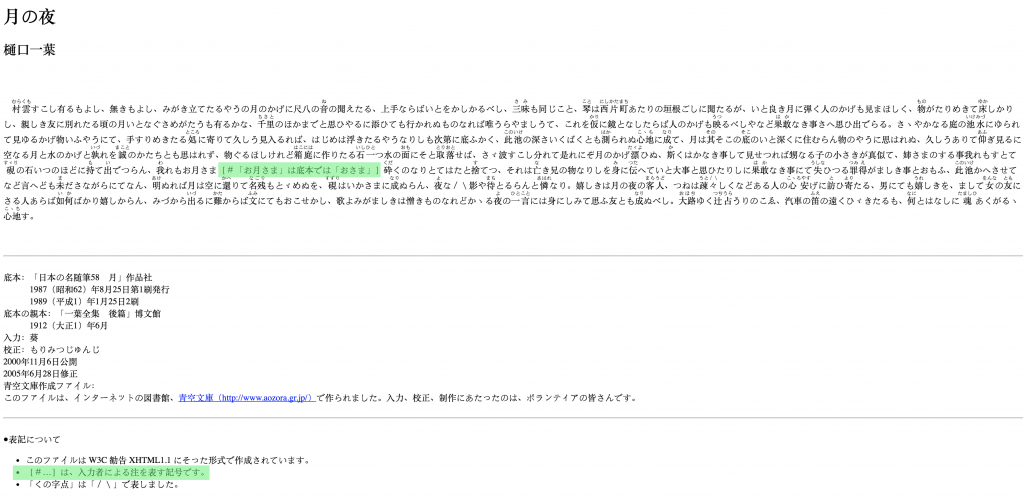
A large majority of Aozora Bunko story entries maintain a shared structure: header information, main text, and bibliographic information. Please see the following example of Higuchi Ichiyō’s short story Tsuki no Yo.

It is possible to isolate the elements that make up each story thanks to the standardized HTML output format of the archive; however, one particular challenge is filtering out all furigana in order to properly mine the text. Furigana is used as a reading aid in Japanese—syllabic characters can be appended to ideographic characters (kanji), especially for kanji that are rare or have a special pronunciation. Within the first few lines of Tsuki no Yo there are several instances of furigana usage.

Behind the scenes this looks a bit messy, and it can be difficult to parse. Furigana entries use ruby characters, a web standard element that behaves as an annotation of sorts for logographic characters. For more information on the ruby specifications, please see the W3C documentation page. The following is an example of Tsuki no Yo viewed as HTML.

Parsing Aozora Texts
Molly Des Jardin, Japanese Studies Librarian at the University of Pennsylvania, has written a script in Python that will automatically strip the ruby characters from a text. This script and additional resources for Japanese language analysis can be found on her Japanese Text Analysis library guide. In order to run this script you will need Python installed on your computer, and in addition you will need to install the following dependencies: BeautifulSoup & TinySegmenter. If you are new to Python, make sure to install the pip tool, thereafter you can install the two libraries from the terminal as such:
pip install beautifulsoup4
pip install tinysegmenter
import os
import glob
import sys
from bs4 import BeautifulSoup
from tinysegmenter import *
for filename in glob.iglob('*.html'):
# Remove ruby and <rt> <rp> tags from text
with open(filename, 'r') as f:
input = f.read()
print filename
soup = BeautifulSoup(input)
tagname = 'rt'
for tag in soup.findAll(tagname):
tag.extract()
tagname = 'rp'
for tag in soup.findAll(tagname):
tag.extract()
tagname = 'span'
for tag in soup.findAll(tagname):
tag.extract()
nonruby = unicode(soup)
# Remove all HTML tags and attributes, then write the file to (filename).txt
nonruby = re.sub('<[^<]+?>', '', nonruby)
segmenter = TinySegmenter()
tokenized = segmenter.tokenize(nonruby)
tokenized = tokenized[0:(tokenized.index(u'底本'))-1]
tokenized = ' '.join(tokenized)
file = open(filename + '.txt', 'w')
file.write(tokenized.encode('utf-8'))
file.close()
Running Molly’s script is quite simple: place the file into a folder containing the HTML files of each story you would like to parse. From the terminal, simply execute the following command:
python rubydetokenize.py
Please note that this script was designed for Python 2, but can be converted for Python 3 by making small changes to the code (notably, changing the print statements). The script will iterate through the various files to remove all HTML tags and ruby annotations, and will output them as text files with only the text of the story remaining.
Before (tsuki_no_yo.html):
After (tsuki_no_yo.txt):

In order for this script to work correctly on Tsuki no Yo, it was first necessary to add a few lines of additional code. The reason for this is because there is a language usage note made within the text itself, and represented as an HTML <span> element that the script does not originally scan for:
The following code was added to the original script to target any HTML elements called “span,” thereby removing the language usage note entirely. While working with various stories you may discover that there are internal inconsistencies that require you to target specific HTML elements that causing the script to either break or parse incorrectly.
tagname = 'span' for tag in soup.findAll(tagname): tag.extract()
You may also notice that the script tokenizes words, meaning it attempts to group words based on common lexical patterns in Japanese. This work is done by TinySegmentor, one of many parsing tools for East Asian languages. Another useful parsing tool is MeCab, which also works with Python. No parser is 100% accurate (at least not yet), especially for stories within the Aozora database which may contain antiquated morphological patterns that are no longer in use.
Header Image: Harvard Art Museum, 1977.202. “The Former Deeds of Bodhisattva Medicine King,” Chapter 23 of the Lotus Sutra (Hokekyô) Calligraphy.