Hacking Mirador is the first workshop of four in the Arts & Humanities Research Computing Fall 2016 Lunch & Learn series. The goal of this tutorial is to introduce participants to the International Image Interoperability Framework (IIIF) and the open-source IIIF image viewer Mirador. Together these tools support and enhance scholarly publications for the web, digital exhibits, and even course teaching materials.
Although IIIF has been adopted by a growing number of institutions around the world, there does not yet exist a single, common point of access or user interface for working with IIIF content on the fly. For this reason, this and future workshops aim to clarify the research needs of faculty, staff, and students in order to inform the development of a unified workspace going forward.
As a part of this tutorial, participants will learn how to retrieve and edit image manifests from Harvard’s collections, import them into the Mirador viewer, and create annotations for those images. In addition, the workshop features alternative IIIF image collections from partnering institutions and how they can be imported into Mirador as well.
Arts & Humanities Research Computing staff are available for questions, comments, or consultations. To schedule a one-on-one session, please contact us.
International Image Interoperability Framework (IIIF)
 The International Image Interoperability Framework (IIIF) defines universal standards for describing and delivering images over the web, and is the result of collaborative efforts across universities, museums, libraries, and other cultural heritage institutions around the world. In other words, IIIF universalizes the way archived images are described and retrieved. Institutions that provide IIIF endpoints for their materials are able to share these materials with anyone worldwide using a IIIF-compatible viewer. This provides an unprecedented level of exposure for archives and repositories.]
The International Image Interoperability Framework (IIIF) defines universal standards for describing and delivering images over the web, and is the result of collaborative efforts across universities, museums, libraries, and other cultural heritage institutions around the world. In other words, IIIF universalizes the way archived images are described and retrieved. Institutions that provide IIIF endpoints for their materials are able to share these materials with anyone worldwide using a IIIF-compatible viewer. This provides an unprecedented level of exposure for archives and repositories.]
Mirador
 Mirador is a configurable, extensible, and easy-to-integrate image viewer that enables image annotation and comparison of content from repositories around the world. It was designed to display resources from repositories that support the International Image Interoperability Framework (IIIF) APIs.
Mirador is a configurable, extensible, and easy-to-integrate image viewer that enables image annotation and comparison of content from repositories around the world. It was designed to display resources from repositories that support the International Image Interoperability Framework (IIIF) APIs.
The Andrew W. Mellon Foundation generously provided funding to Stanford University for Mirador’s initial development. At present its primary developers are Rashmi Singhal (Harvard University), and Drew Winget (Stanford University). The ongoing specification of the IIIF architecture is carried out by a team of software architects led by Rob Sanderson of the Getty Trust.
Adoption at Harvard University
Participating IIIF partners at Harvard University include the Harvard Library, the Harvard Art Museums, HarvardX, individual faculty members, and others. In addition, Arts & Humanities Research Computing maintains Harvard’s official IIIF presence and continues to pioneer the adoption and use of IIIF on campus.
In early 2016, the Harvard Library officially replaced its Page Delivery Service (PDS) with Mirador, making it the default viewer for image content accessed through HOLLIS, the library collection search engine. For example, when viewing the item record for the fifteenth century manuscript Horae beatae Mariae virginis, clicking the view online option will open the image directly within Mirador.
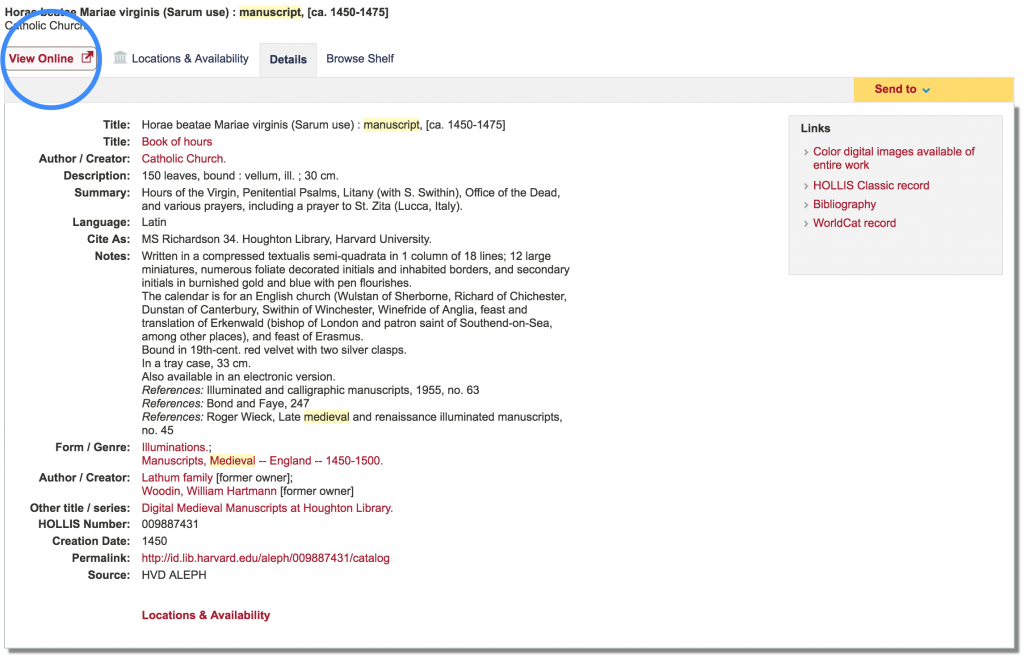
Item record for Horae beatae Mariae virginis
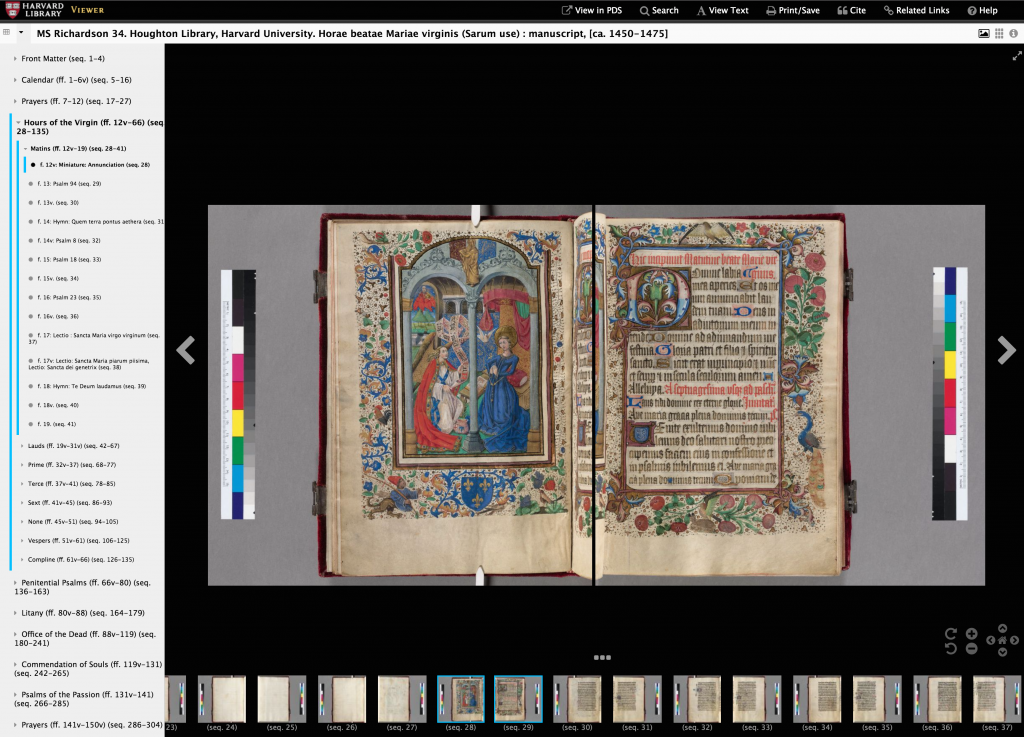
Mirador instance of Horae beatae Mariae virginis
The Anatomy of IIIF Objects
IIIF objects are more than just images, but rather a collection of data described by manifests, “resources that represent a single object and any intellectual work or works embodied within that object. In particular it includes the descriptive, rights, and linking information for the object. It then embeds the sequence(s) of canvases that should be rendered to the user” (IIIF Presentation API 2.0). In other words, IIIF manifests describe an object’s metadata, how to access the image(s) within the object, and the order in which they should appear. Mirador and other IIIF viewers are designed to parse these manifests to understand precisely which image should appear and in what format.
Manifests are encoded in JavaScript Object Notation (JSON), an open-standard format that uses human-readable text to transmit data on the web. The next section will introduce how to work with image manifests, and while it is not necessary for scholars to be able to write their own manifests, closer inspection of an example manifest reveals that it is largely readable by a non-technical audience:
{
license: "Use of this material is subject to our Terms of Use: http://nrs.harvard.edu/urn-3:hul.ois:hlviewerterms",
structures: [],
sequences: [],
related: "http://id.lib.harvard.edu/aleph/009887431/catalog",
label: "MS Richardson 34. Houghton Library, Harvard University. Horae beatae Mariae virginis (Sarum use) : manuscript, [ca. 1450-1475]",
@context: "http://www.shared-canvas.org/ns/context.json",
logo: "https://iiif.lib.harvard.edu/static/manifests/harvard_logo.jpg",
@id: "https://iiif.lib.harvard.edu/manifests/drs:6135067",
@type: "sc:Manifest"
}
Making Use of Harvard Resources
In order to access a particular IIIF manifest for an item in Harvard’s collections, first navigate to the Mirador instance for that item. In other words, click the “view online” option from the HOLLIS record (see above). Here is an example Mirador instance URL:
https://iiif.lib.harvard.edu/manifests/view/drs:6135067$1i
From this page you can edit the URL in your browser to reveal the manifest that informs the instance. Remove the elements in bold from the original address (view/ and $1i).
You may notice while browsing a manuscript that the content following the ‘$’ changes in response to which page of the manuscript you are currently viewing. It is possible to instruct Mirador to open an image object to a specific page using this notation in the URL.
Once you have edited the URL it should look like the following:
https://iiif.lib.harvard.edu/manifests/drs:6135067
This will work for any Harvard IIIF object. The next step is to feed this manifest into a IIIF viewer. To access Mirador there are two options:
Please note that anything loaded into the DARTH instance of Mirador will not be saved. Once Mirador is up and running, you can click the “Add Item” button and insert the manifest URL at the top.

This will cause the item to appear in the table of contents where it can be selected for viewing.

Additional Sources for IIIF Content
The example at the start of the article, Beethoven’s Symphony Number 9 in D Minor, belongs to the World Digital Library, a project of the Library of Congress and member of the IIIF community. Individual item records, such as in the case of Beethoven’s ninth, include a direct link to the object’s IIIF manifest. The World Digital Library contains everything from Noh libretti to treatises on quantity conversions between Roman and Egyptian measurements.
Another example resource is e-codices, the Virtual Manuscript Library of Switzerland, which provides free access to Switzerland’s medieval manuscript collections. One example, shown below, is the Daily Prayer Book According to the Sephardic Rite.
Additional resources and content can be found on the IIIF community website.
Editing Manifests
It is often the case that only select pages or images are needed from a single manifest rather than its entirety. Currently there are two ways to edit a manifest to include only specific information. The first way is to manually edit the JSON in the manifest to remove/rewrite unwanted information. The second option is to use a IIIF manifest editor. The Bodelian Libraries at the University of Oxford recently released one such editor, which can be downloaded from its GitHub repository, or accessed via the DARTH website.
Selecting the “open manifest” option and pasting the URL to a JSON manifest will open it within the editor.
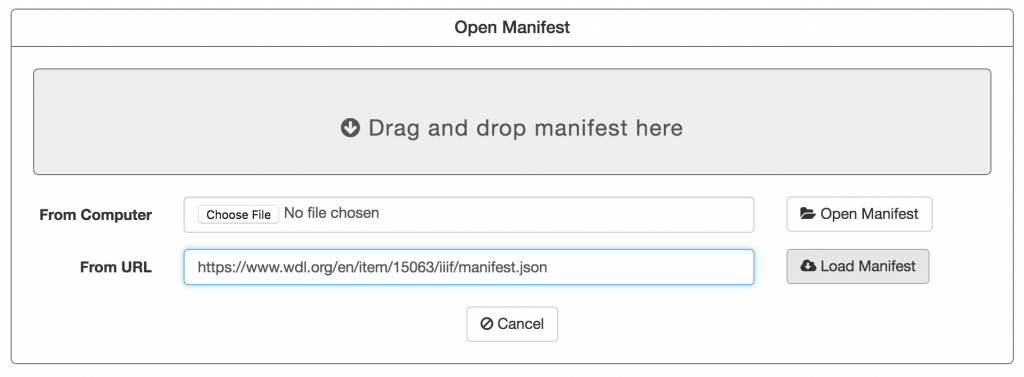
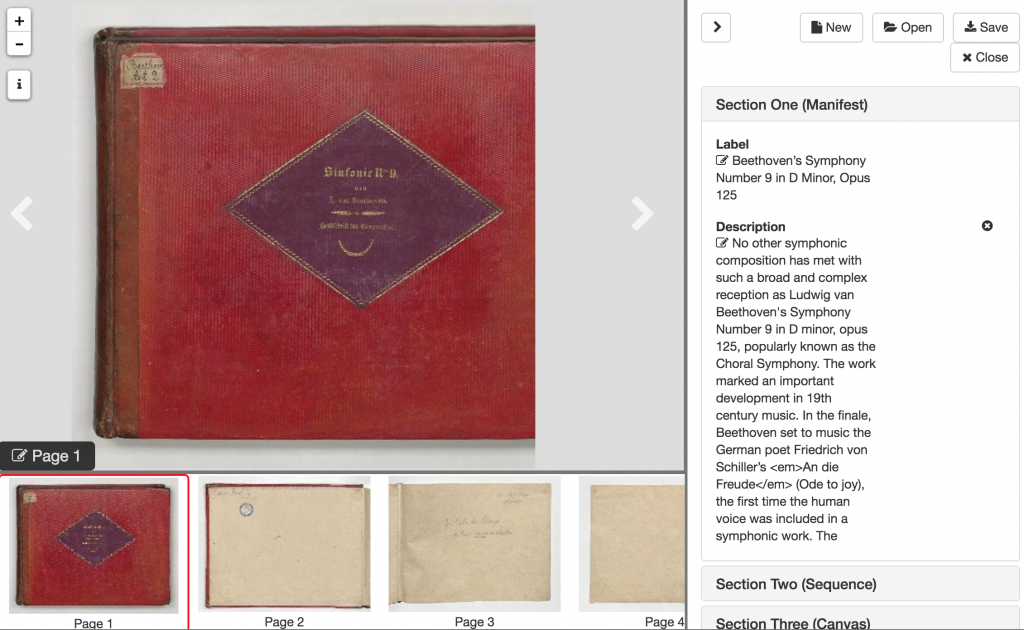
From the editor users can make changes to the metadata, reorder the sequence of canvases (by dragging the thumbnails in the bottom panel), delete/add canvases, and save changes into a new manifest file. Make sure to save all changes into a .json file or it will be unreadable by Mirador.
Additional information about how to use the editor can be found on the IIIF Manifest Editor GitHub page.
Annotations
To annotate within Mirador, look for the speech bubble icons in the top-left corner of the Mirador interface. This will open a set of annotation options including shape and color tools. Users can draw boxes, circles, polygons, pins, or even free draw shapes of their choice. Annotations can be associated with multiple drawings, and tags can be added to those annotations.
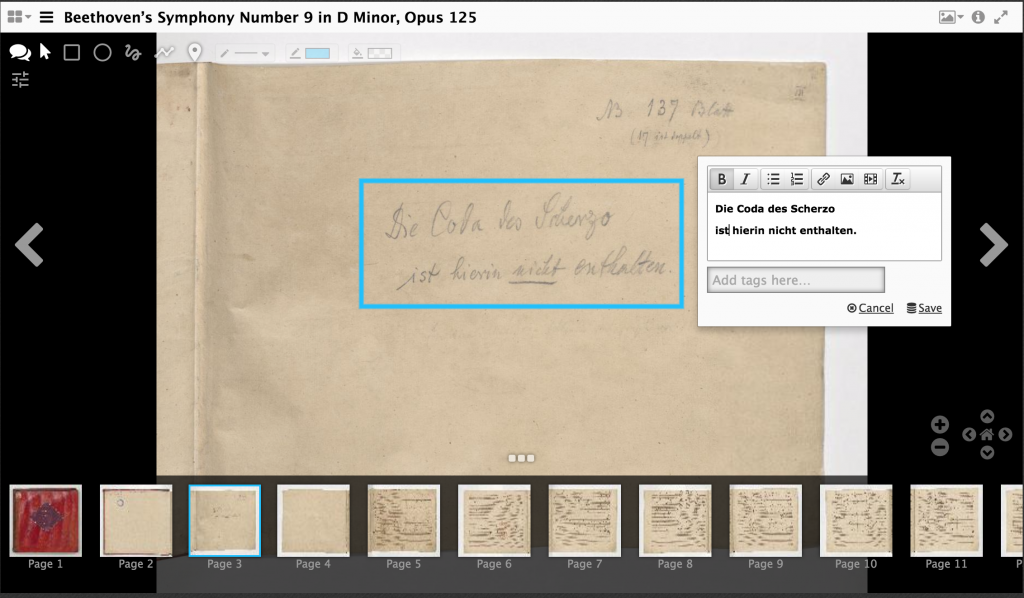
There are currently two methods for saving annotations: the first is to connect Mirador to a database that can manage storage and retrieval. This is an ideal approach for large projects and courses with multiple annotators, but also the most technically challenging to configure. Advanced users can learn more about how it’s done at the Mirador GitHub repository. An alternative approach, which will be discussed here, demonstrates how users can create static annotations and associate them with a IIIF manifest. This method is easier to manage and setup, but requires some manual editing of the original manifest.
When annotating in Mirador, the browser automatically saves all of that annotation data within its local storage. Using a parsing tool such as this one, all of the annotation information can be extracted directly from the browser and formatted as a list of annotations, one list per page.
As an example, begin by copying and pasting a manifest URL into the text field (e.g. Beethoven’s ninth: https://www.wdl.org/en/item/15063/iiif/manifest.json) and select load manifest. Complete all annotations within this interface, but note that quitting the browser or loading a new manifest will delete previous annotations. The parsing tool resets the local storage with each new manifest it loads in order to retrieve only annotations from the current document.
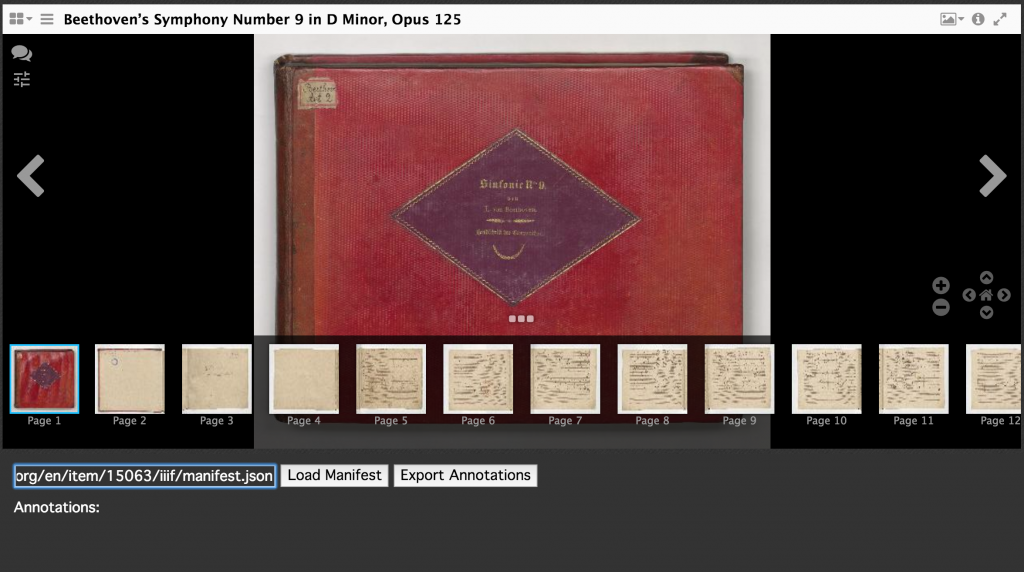
Insert manifest URL
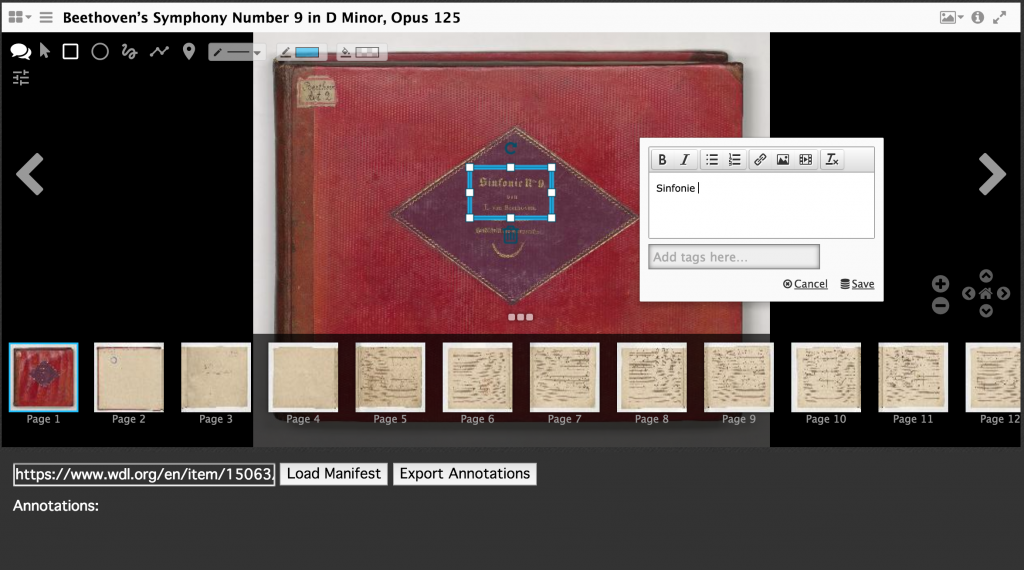
Annotate as usual
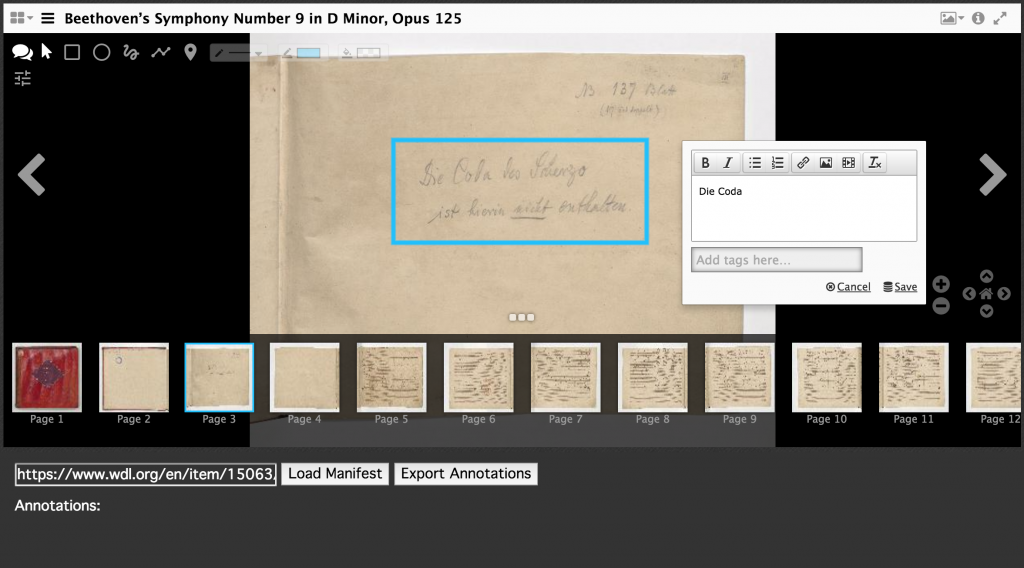
Mirador will create one entry per page of annotations, no matter how many annotations exist on one page
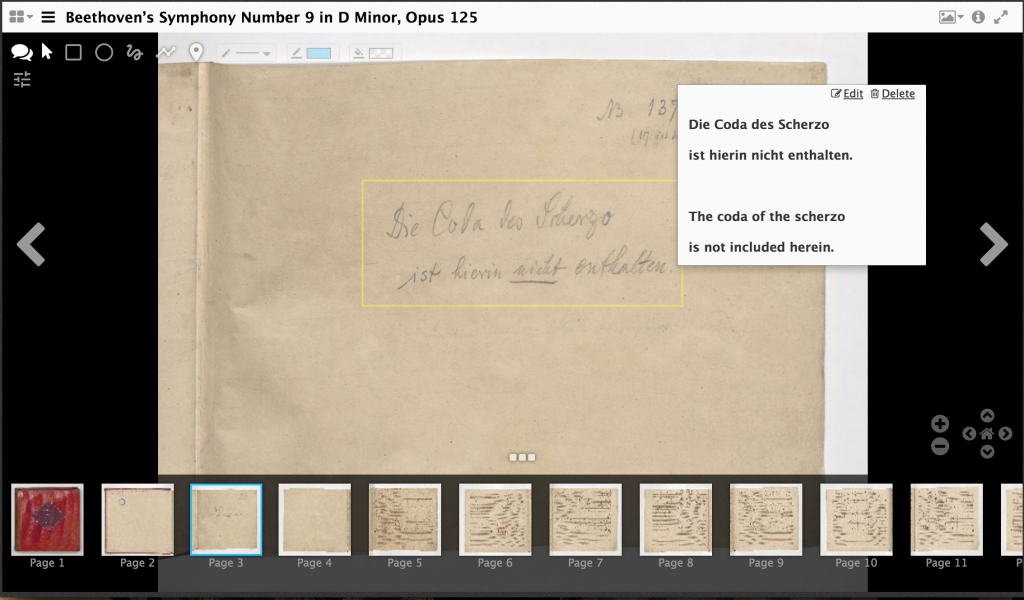
After selecting the export annotations button, a list of links will appear at the bottom of the screen. Each of these represents one canvas’s worth of annotation data. Clicking a link will open a new browser window with the JSON data printed out. You will need to copy and paste this data to a text editor of your choice for some minor tweaking before saving it.
An annotation object is composed of a number of elements: at least one shape, the text of the annotation, tags, and location information regarding which canvas and where on the canvas to appear. In the case of the example above, there will be two separate entries in the browser local storage, one for annotations made on page one, and one for annotations made on page three.

Annotation data for page one; this must be copied and pasted into a text editor and saved as a .json file
In order for the annotations to appear you will need to make a few simple changes to the code. For those unfamiliar with JSON, this unformatted version can be difficult to read. Copy and paste the code either into a text editor that has a JSON formatter, or use the following tool to beautify it: JSON Formatter.
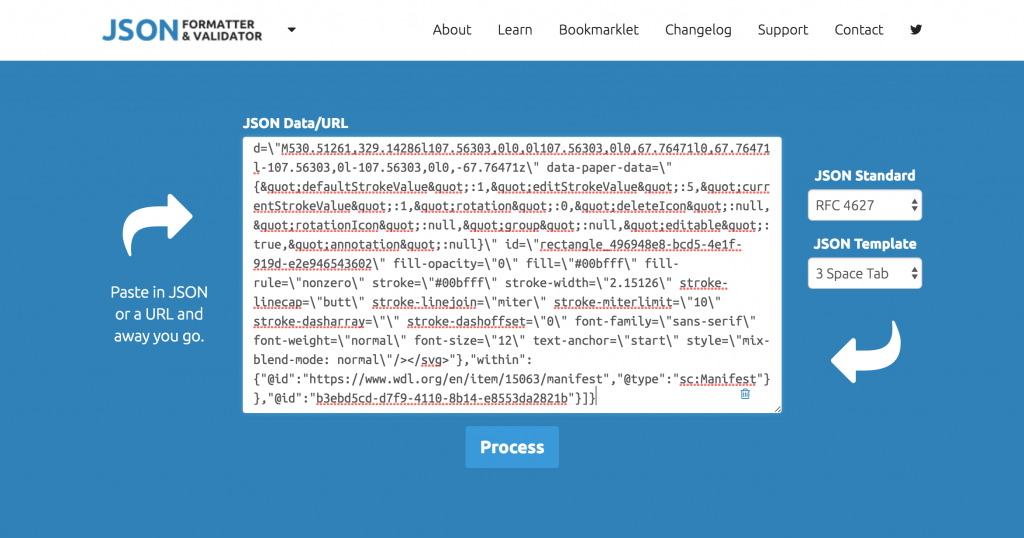
Copy and paste JSON code into the formatter
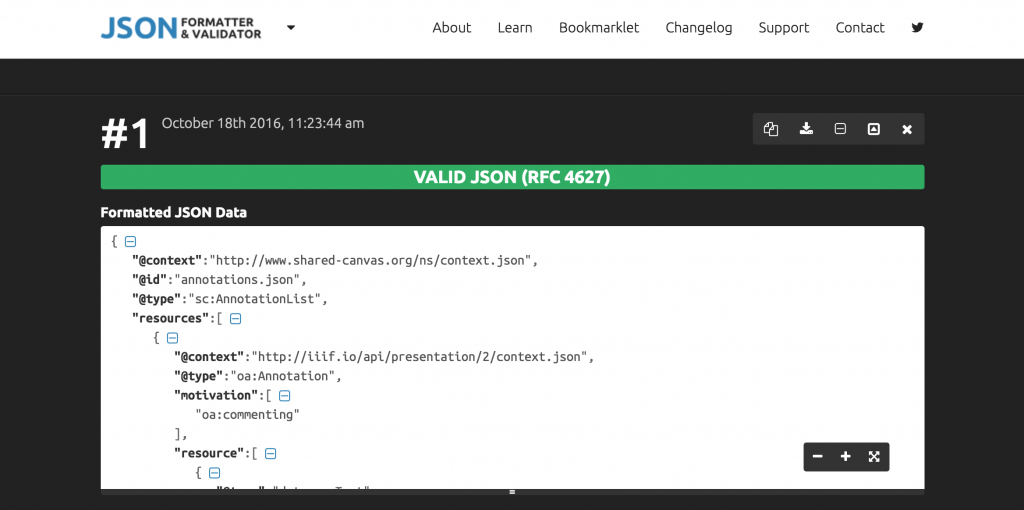
Retrieve formatted code below and copy into a text editor
Now that the code is formatted, look for the @id tag that appears within the first few lines. The value of that tag is currently set to annotations.json, but will need to be renamed to fit the URL where this particular annotation file will live. For this example, the annotations for this project will live at darthcrimson.org/hacking-mirador-workshop/, and since this is the first canvas in the series, the URL should therefore be: http://www.darthcrimson.org/hacking-mirador-workshop/canvas1.json. You will need to download each page of annotations from the parser tool and change the @id values accordingly. Once this is done, save the file as canvas1.json (or in the case of page three, canvas3.json).
Finally, it is necessary to open the manifest file itself and make a few changes in order to associate each of the annotation files with their respective images. This means you will either have to download the custom manifest you built within the manifest editor, or if you are not building a custom manifest, simply download the manifest file from the institution that hosts it (e.g. Beethoven’s ninth: https://www.wdl.org/en/item/15063/iiif/manifest.json).

The entry for the first canvas within the Beethoven manifest
Manifests contain individual entries for each canvas, and the goal here is to find the entry for each canvas that has annotations associated with it. The screenshot above reveals an entry for the first canvas, which can be ascertained most easily via the last three lines:
label: "Page 1",
@id: "https://www.wdl.org/en/item/15063/iiif/sequence/1/canvas/1/",
@type: "sc:Canvas"
This is where you can create a reference to any annotations you’ve created for this particular canvas. After @type: “sc:Canvas”, add a comma and the following lines:
otherContent: [{
@id: "http://darthcrimson.org/hacking-mirador-workshop/canvas1.json",
@type: "sc:AnnotationList"
}]
Once the reference has been added, it should look like this:

You will need to do this for each canvas within the manifest that has annotations. Once you have made the edits, save the manifest and upload it to the web with the associated annotation files. Now whenever you access the manifest from within Mirador, it will automatically include the annotations you’ve made along with it, as in the example below.
Final Thoughts
Harvard has made great strides in its adoption and use of IIIF, and although many of the tools discussed here are still quite new, they have begun to bridge the gap between technical and non-technical audiences working with IIIF material. Going forward, Arts & Humanities Research Computing will continue support and development of Mirador and other tools that enable scholars to work with in more efficient and user-friendly ways.